-
728x90
배열
0 1 2 3 … 9270 … 9999 Koguri@koguri.com 배열은 원소 하나를 저장하거나 검색할 때 자료의 개수와 비례하는 시간이 걸리게 됩니다.
koguri@koguri.com이 맞는지 확인할때 하나하나 비교해야하기 때문에 O(N)의 시간이 걸리게됩니다.
배열보다 조금 더 빨리 자료를 저장, 검색 할 방법은 없을까? 란 고민 끝에 나온 자료구조가 트리입니다.
트리
트리는 원소 하나를 저장하거나 검색하는 데 평균 O(logN)의 시간이 걸립니다. 레드 블랙 트리처럼 균형 잡힌 트리는 최악의 경우에도 O(logN)의 시간이 걸리게 됩니다. 하지만 트리도 자료의 크기가 커지면 저장 및 검색에 오랜 시간이 걸리게 됩니다.
저장된 자료의 양에 상관없이 원소 하나를 저장하고 검색하는 것을 상수 시간에 가능하게 할 수는 없을까? 란 고민 끝네 나오게 된 것이 HashTable입니다.
해시 테이블
임의의 원소를 해시 테이블에 저장하는데 방식은 아래와 같습니다.
1. 해당 원소에 해시값을 해시 함수를 이용하여 계산한다.
2. 이 해시값을 주소로 하는 위치에 원소를 저장한다.
3. 저장 후에 검색을 할 때도 원소의 해시값을 계산해 바로 해당 위치로 이동한다.
이렇게 해서 테이블은 원소를 저장할 위치를 상수 시간에 계산할 수 있다.
해시 함수
임이의 길이의 데이터를 고정된 길의 데이터로 매핑하는 함수를 해시 함수라고 한다.
ex) h(x) = x mod 13
해시 함수에 값을 넣어서 나오는 함수 값을 해시값, 해시라고 부르며 이 해시값을 구하는 과정을 해싱이라고 부릅니다.
위의 예에 x는 어떤 값을 넣을 수 있지만 나오는 결과 값의 범위는 정해져있다.
좋은 해시 함수의 조건
- 계산이 간단해야 한다.
- 입력 원소가 해시 테이블 전체에 고르게 저장되어야 한다.
- 일부에 너무 몰리게 되면 해시 충돌이 발생할 수 있다.
해시 충돌
해시 함수가 서로 다른 두 개의 입력값에 대해 같은 출력값을 내는 상황
ex) hx(x) = x mod 13에서
x = 7 은 값이 6
x = 19 도 값이 6 이므로 같은 곳에 저장하려고 한다.해시 충돌을 해결하는 방법은 2가지가 있습니다.
1) 체이닝

https://www.researchgate.net/figure/Example-of-Separate-Chaining-Method_fig2_283760058 - 같은 주소로 해싱되는 원소를 모두 하나의 연결 리스트에 매달아서 관리합니다.
- 원소를 검색할 때는 해당 연결 리스트들의 원소들을 차례대로 지나가며 탐색합니다.
- 충돌은 해결 할 수 있지만 리스트를 또 탐색해야 하는 문제가 발생한다.
2) 개방 주소 방법(open addressing)
- 체이닝과 달리 어떻게든 주어진 테이블 공간에서 해결한다.
- 따라서 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장이 없다.
- 선형 조사(linear probing), 이차원 조사(quadratic probing), 더블 해싱(double hashing)이라는 방법이 있습니다.
2-1) 선형 조사(linear probing)

https://www.geeksforgeeks.org/implementing-hash-table-open-addressing-linear-probing-cpp/ - 충돌이 일어난 자리에서 i에 관한 일차 함수의 보폭으로 점프한다.
- hi(x) 는 h(x) 에서 i만큼 떨어진 자리이다.
- 경계를 넘으면 맨 앞으로 넘어간다.
- 쉽게 말해서 내 자리에 값이 있다면 다음칸 그칸에도 값이 있따면 다음칸을 반복해 비어있는 칸에 넣으면 된다.
- 공간이 채워지면 채워질수록 연산 횟수가 매우 늘어나게 된는 큰 단점이 존재합니다.
2-2) 이차원 조사(quadratic probing)
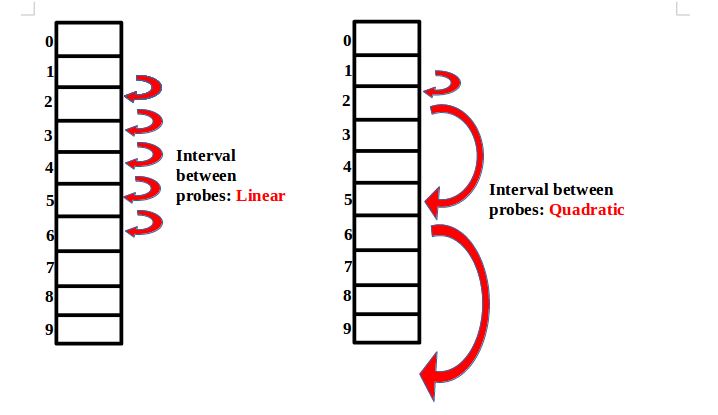
https://www.codingeek.com/data-structure/complete-guide-open-addressing-classification-eliminate-collisions/attachment/linear-and-quadratic-probing/ - 충돌하면 보폭을 2차 함수로 넓혀갑니다.
- h(x) 에 값이 존재한다면 h(x) + 1 > h(x) + 4 > h(x) + 9 > h(x) + 16 > ...
- 단점으로는 h(x)에 값이 존재한 경우가 100번 존재한다면 100번째 값은 99번째가 갔던 모든 경로를 간 후에 본인의 자리를 알 수 있다.
2-3) 더블 해싱(double hashing)
- 두 개의 해시함수를 이용합니다.
- 하나의 함수는 최초의 해시값을 얻을 때, 다른 하나는 충돌이 일어났을 때 이동할 폭을 결정할 때 사용합니다.
- 두 원소의 첫 번째 해시값이 같더라도 보폭까지 같을 확률은 매우 낮아 다른 보폭으로 점프 할 수 있습니다.
해싱 함수의 특징
- 같은 입력값에 대해서 같은 출력값이 보장된다.
- 서로 다른 입력값으로부터 동일한 출력값이 나올 가능성이 희박하므로 입력값에 대한 무결성이 보장된다.
- 일방향성을 갖는다. (해시함수를 통해서 원래 값을 역 추적하는게 불가능하다.)
Secure Hash Algorithm(SHA)
- NSA(미국 국가안보국)에 의해 1993년 처음 개발된 해시 알고리즘
- 현재는 주로 SHA-2 함수를 사용합니다. 다이제스트의 길이에 따라 SHA-256, SHA-512 등으로 나눌 수 있습니다.
* 암호학에서 다이제스트(digest)는 임의 길이의 데이터 블록을 고정 길이로 변환하는 해시 알고리즘에서의 해시값을 가리킨다.
- 여기서 SHA 뒤의 숫자 256의 의미 : 해싱을 하면 2^256 개의 해시값 중 하나가 나타나게 됩니다.
- 해시값은 입력값에 아주 작은 차이만 존재해도(. 하나의 차이) 아예 다른 값이 된다.
해시는 어디에 응용할 수 있을까?
- 무결성 검사 : 파일이 변했는지 해시값을 통해 확인 할 수 있다.
- 클라우드 스토리지에 동일한 파일 식별 및 수정된 파일 검출
- 데이터베이스에 비밀번호를 저장할 때 사용
- 블록체인
- Git
참고
https://www.youtube.com/watch?v=Rpbj6jMYKag
728x90